Tomáš Hobza 6.F, 2022 - Maturitní otázky z Programování
Algoritmizace úlohalgoritmusvlastnosti algoritmuprogramzpůsoby vyjádření algoritmuabstrakcedekompoziceProgramovací jazyk - jazykové konstrukcepojmyjazykové konstrukcepříkazyProgramovací jazyk - podprogramyprototyp funkce, návratová hodnota, parametryparametrylokální a globální proměnnézásobník a fungování podprogramuProgramovací jazyk – práce se souboryproměnná pro práci se souboremzpůsoby otevírání souborů (módy)operace pro práci se souboremZobrazení dat v počítačipojem informace, jednotky pro měření informacečíselné soustavy, převody mezi soustavamipřímý, inverzní, doplňkový kódFormální jazyky, automaty pojmydělení jazykůChomského hierarchie gramatik způsoby popisu jazykuGramatikypojmyvztah mezi jazykem, gramatikou a konečným automatemChomského hierarchie gramatikModel počítače, strojové jazykyStruktura a funkce procesoru: registry, řadič, ALUvon Neumannovo schéma, Harvardská architekturainstrukční cyklusjazyk symbolických adres, assemblermetody adresování pamětimodel pamětiDynamické datové strukturypojem abstraktní datový typKonstrukce základních dynamických datových struktur a operace s nimiHromadné zpracování dat, databázeProč HZD? Úlohy HZDOrganizace souborů z pro hromadné zpracování dat (tj. obrovské soubory), přístup k souborůmSoučásti databázeEliminační metody pro řešení soustav n lineárních rovnic o n neznámýchpojmyvyjádření soustavy lineárních rovnic pomocí maticGaussova eliminační metodaGauss-Jordanova eliminační metodaIterační metody pro řešení soustav n lineárních rovnic o n neznámýchpojmyiterační výpočetJacobiho iterační metodaGauss-Seidelova iterační metodaŘešení nelineárních rovnicpojmyvyčíslení polynomu Hornerovým schématemdefinice úlohy řešení nelineárních rovnicmetodyMetoda nejmenších čtvercůpojmyprincipodvození pro konstantní a lineární funkciMetody vnitřního řazenívlastnosti řadících algoritmůalgoritmyprincip ostatních metodMetody vnitřní řazeníspecifika vnějšího řazenípojmypřímé a přirozené řazenímetody zlepšováníprincip polyfázového slučováníVyhledávací algoritmypojmysekvenční vyhledáváníbinární vyhledáváníhašovací tabulkaprincip index-sekvenčního vyhledáváníbinární vyhledávací stromsrovnání vyhledávacích metodObjektově orientované programovánípojmyzapouzdření, dědičnost, polymorfismuspraktické použití OOPOperační systémystruktura OS (vrstvy)modulární OSmultitaskingprocesy, vlákna, životní cyklus procesuPočítačové sítě - hardwarerozdělení sítídruhy sítítopologieprvky sítěmetody přístupufunkce počítačové sítěPočítačové sítě - softwaremodel ISO/OSImodel TCP/IPprotokolyinternetBooleova algebra a její využitízákladní pojmylogické funkcezákonyvyjadřování logických funkcíminimalizace logických funkcí
Algoritmizace úloh
algoritmus
- popis postupu řešení daného problému
vlastnosti algoritmu
- jednoduchý (elementární, jeden příkaz = jeden význam)
- konečný
- resultativní (vede k výsledku)
- deterministický (jednoznačný, stejné parametry = stejný výsledek)
program
- zápis algoritmu, aby mu rozuměl procesor
- procesor = ten/to, co vykonává algoritmus
způsoby vyjádření algoritmu
- slovní popis, vývojové diagramy, programovací jazyk
abstrakce
- princip řešení problému
- řešení problému skládáním řešeních menších problémů
- zdola nahoru
dekompozice
- princip řešení problému
- rozdělení řešení velkého problému na řešení malých částí problému
- shora dolů
Programovací jazyk - jazykové konstrukce
pojmy
deklarace
- prohlášení existence
- proměnné s daným typem a jménem
definice
- příkaz
- vyrobí danou proměnnou v paměti
inicializace
- první přiřazení hodnoty do proměnné
- neinicializována proměnná má nedefinovanou hodnotu
jazykové konstrukce
proměnná
- pojmenovaná paměťová buňka
- má datový typ
- její hodnota se může měnit (narozdíl od konstanty)
- global/local
datový typ
definuje druh jakých hodnot smí proměnná nabývat
dělení:
složené (složené z jiných datových typů)
- homogenní (pole integerů)
- heterogenní (objekt)
jednoduché
ukazatelové (obsahují adresu paměťového místa)
- typové
- netypové (nemají typ, jen ukazují na místo pomocí voidu)
příkaz
nejmenší samostatný prvek programu
vyjadřuje činnost, která má být provedena
obsahuje proveditelný kód
skládá se z výrazů
dělení:
- jednoduchý
- složený (blok, obsahuje jeden nebo více příkazů)
výraz
má nebo reprezentuje hodnotu konkrétního typu
dělení:
L-hodnota
- výraz může být na obou stranách přiřazovacího operátoru
- př.: x = a+b
P-hodnota
- výraz, který může být pouze na pravé straně přiřazovacího operátoru
- př.: x = a+b
důležité operátory:
dereferenční operátor (*)
- vrací hodnotu paměťové, na níž odkazuje ukazatel
- celý výraz je L-hodnota
referenční operátor (&)
- vrací adresu proměnné nebo výrazu
- celý výraz je P-hodnota
operátor indexování pole ([])
- celý výraz je L-hodnota
operátor přístupu ke složce struktury (.)
- celý výraz je L-hodnota
operátor přístupu ke složce přes ukazatel na strukturu (->)
- celý výraz je L-hodnota
operátor volání funkce (())
- bez něj je výraz chápán jako ukazatel na funkci
podprogram
- jazyková konstrukce, která označuje část programu, kterou jde opakovaně zavolat
příkazy
větvení
rozdělení průběhu programu na základě nějaké podmínky
pro zápis podmínky používáme relační operátory (<, <=, >, >=) nebo operátory rovnosti (==, !=)
příkazy:
if
- začíná klíčovým slovem if, za kterým následuje výraz typu boolean
- může obsahovat větev else, která se provede, pokud podmínka vrátí nepravdu
- je-li větev na více řádcích, použijeme blok
switch
- nahrazení zřetězených příkazů if
- obsahuje návěstí (case)
cykly
opakování příkazů v závislosti na ukončovací podmínce nebo předem daném počtu opakování
dělení:
s pevným počtem opakování (for)
- provede se tolikrát, jak určuje rozsah řídící proměnné
s podmínkou na začátku (while)
- v případě, že již na začátku neplatí podmínka, nepovede se vůbec
s podmínkou na konci (do … while)
- vždy se provede alespoň jednou
Programovací jazyk - podprogramy
prototyp funkce, návratová hodnota, parametry
prototyp funkce
- “hlavička”
- uvedení návratové hodnoty, identifikátoru a seznamu parametrů bez těla funkce
návratová hodnota
- hodnota, kterou podprogram vrací
- její datový typ je určený datovým typem podprogramu (funkce)
druhy podprogramů
funkce
- vrací návratovou hodnotu
procedura
- nevrací návratovou hodnotu
parametry
vstupní data podprogramu
druhy:
formální
- vnitřní proměnná
- parametr použitý při psaní funkce
- je vždy před zpracováním nahrazována hodnotou skutečného parametru
skutečný
- proměnná nebo výraz dosazený při volání podprogramu
- při volání podprogramu je jeho hodnota přiřazena formálnímu parametru
dělení dle způsobu předávání:
hodnotou
- skutečný parametr se před zpracováním podprogramu vyčíslí a výsledek se zkopíruje do lokální proměnné uvnitř volaného podprogramu
- lokální proměnná po skončení podprogramu zanikne
- není možné upravovat proměnnou, která byla předána jako skutečný parametr
odkazem
- formální parametr je jen jiné označení (alias) pro proměnnou předanou jako skutečný parametr
- předávání odkazem lze použít i jako vstupně-výstupní parametr
lokální a globální proměnné
lokální
- existují jen v rámci podprogramu či bloku, ve kterém byli definované
globální
- existují v celém programu od místa, kde byli definované
- zastínění globální proměnné = lokální proměnná se stejným jménem jako globální má větší prioritu v podprogramu, kde lokální proměnná existuje
zásobník a fungování podprogramu
zásobník (volání)
- ukládají se zde lokální proměnné a informace týkající se provádění podprogramu
fungování
- podprogram funguje podle to co mu uživatel zadá, vyrábí se na něm lokální proměnné, vytvoří se nový v vnoření
Programovací jazyk – práce se soubory
proměnná pro práci se souborem
soubor
souvislá, sekvenční posloupnost bajtů
má jméno a umístění
pamatuje si délku v souborovém záznamu (nemá na konci značku konce)
souborový záznam
- obsahuje jméno, délku a umístění prvního fyzického bloku souboru
proměnná typu ukazatel na soubor
- obsahuje adresu na souborový záznam
způsoby otevírání souborů (módy)
standardní
- r - otevře existující soubor pro čtení
- w - vytvoří soubor pro zápis (nebo přepíše existující)
- r+ - otevře existující soubor pro čtení a zápis
- w+ - vytvoří soubor pro zápis a čtení (nebo přepíše existující)
speciální
- a - otevře soubor pro připisování na konec
- a+ - otevře soubor pro připisování a zároveň čtení (pokud neexistuje, vytvoří nový)
- rb, wb - pro binární soubory ve Windows
operace pro práci se souborem
otevření
- v jazyce C: fopen()
čtení
po znacích
- v jazyce C: fgetc()
formátované
- v jazyce C: fscanf()
zápis
po znacích
- v jazyce C: fputc()
formátované
- v jazyce C: fprintf()
uzavření
- v jazyce C: fclose()
Zobrazení dat v počítači
pojem informace, jednotky pro měření informace
informace
srozumitelná a smysluplná data
interpretace dat a vztahů mezi nimi
kvantitativní vyjádření obsahu zprávy
data
- vše, co mohu zaznamenat smysly
- surová data, údaje získané měřením, pozorováním, atd.
- objem dat se měří v bitech a bajtech
jednotky pro měření informace
- měří se v bitech
číselné soustavy, převody mezi soustavami
dělení:
poziční
- vyjádření číselné hodnoty pomocí číslic
- řád číslice odpovídá její pozici
- počet možných číslic odpovídá základu dané soustavy
nepoziční
- např.: římské číslice
- neznají nulu
- složité počítání
určení, vyčíslení hodnoty
- polynomiální zápis
- hornerovo schema
převody mezi soustavami
přímý, inverzní, doplňkový kód
kódování celých čísel
přímý kód
- nejvyšší bit je znaménkový
- nevýhody: dvě nuly, obvody pro odečítání
inverzní kód
- nejvyšší bit je znaménkový a záporné číslo je negací kladného
- při počítání je třeba přičíst přenos z nejvyššího řádu
- nevýhody: dvě nuly
doplňkový kód
- nejvyšší bit je znaménkový a záporné číslo je negací kladného s přičtenou jedničkou
- výhody: jen jedna nula
kódování desetinných čísel (nikdy nebudou přesné, nejde mít nekonečno desetinných míst)
standard IEEE 754
znaménkový bit, exponent, mantisa
- znaménkový bit - 0 = kladné, 1 = záporné
- exponent - v aditivním kódu, počet desetinných míst posunutí čárky v mantise
- mantisa - desetinný rozvoj čísla v normalizovaném tvaru
Formální jazyky, automaty
pojmy
syntaxe
- soubor pravidel pro zápis jazyka
- může být vyjádřena gramatikou, syntaktickým diagramem, …
sémantika
- význam vět a slov jazyka
- (programu dává význam člověk)
řetězec
- shluk symbolů abecedy
věta
- řetězec symbolů nad abecedou
- prázdná věta = 𝛆
(formální) jazyk
množina vět (textových řetězců) nad danou, konečnou abecedou
značí se symbolem L
pro jeho popis se používá obvykle gramatika a automat
značení jazyků:
∑*
- jazyk všechny možných vět nad abecedou ∑
- nekonečný jazyk
- nemá gramatiku -> jakýkoliv řetězec je věta
A*
- ∑* nad abecedou A
- jazyk všech možných vět nad abecedou A včetně prázdného řetězce
A+
- jazyk všech možných vět nad abecedou A kromě prázdného řetězce
An
- jazyk všech vět o délce n nad abecedou A
dělení jazyků
rozdělení:
- konečné - lze ho vyjmenovat (konečný počet vět)
- nekonečné - nelze ho vyjmenovat (popisuje se generativně)
Chomského hierarchie gramatik

způsoby popisu jazyku
deklarativní popis:
výčet
vyjmenování všech vět
- lze jen pro konečné jazyky
generativní popis:
syntaktický diagram
grafický popis syntaxe
používané symboly: terminály, nonterminály, šipky
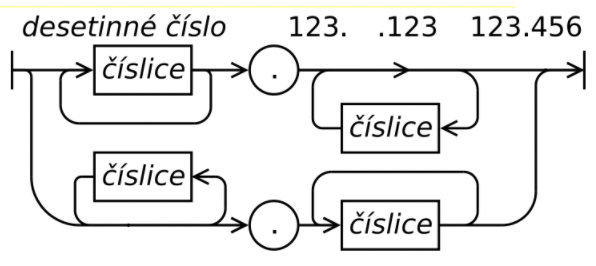
EBNF - rozšířená Backus-Naurova forma
používáno pro popis syntaxe programovacích jazyků
non-terminály - zapisují se slovně (písmeno, číslice, příkaz-if)
terminály - jsou uvozeny uvozovkami
pravidlo
- na levé straně může být jen jeden non-terminál
- na pravé straně mohou být terminály i non-terminály
- např.:
nonterminál = varianta1 | varianta2 | varianta 3 ;
symboly v pravidlech
=- odděluje levou a pravou stranu pravidla|- varianta, z non-terminálu lze jít jednou z více cest;- středník ukončuje pravidlo,- čárka ukončuje sekvenci- např.:
slovo = "a", "h", "o", "j"
- např.:
{}- výraz, který lze opakovat 0 a vícekrát- např.:
číslo = číslice, { číslice } ;
- např.:
[]- výraz, který lze opakovat 0 nebo 1 krát- např.:
[+], číslo |['-'], číslo
- např.:
()- seskupení, podvýraz- např.:
přiřazení = identifikátor , '=' , (číslo | identifikátor | řetězec) ;
- např.:
-- mínus vyjadřuje výjimku- např.:
řetězec = '"' , { znak − '"' } , '"' ;
- např.:
příkaz
if-else- např.:
příkaz if-else = 'if', '(', výraz, ')' , příkaz , [ 'else' , příkaz ];
- např.:
identifikátor
- např.:
identifikátor = znak , { znak | číslice };
- např.:
blokový příkaz
- např.:
blok = '{' , { příkaz } , '}' ;
- např.:
gramatika
- matematická struktura popisující (generující) formální jazyk LG
- LG značí jazyk generovaný gramatikou G
- konečným počtem konečných pravidel dokáže popsat i nekonečné jazyky
konečný automat
automat
algoritmický matematický stroj
slouží k rozhodování zda řetězce jsou věty daného jazyka
Turingův stroj
- teoretický model nejobecnějšího počítače
- umí řešit všechny algoritmicky řešitelné problémy.
zjednodušený automat s konečným počtem stavů
využití:
- přijímání a zpracování nejjednodušších (regulárních) jazyků
- řešení problémů, které lze formulovat tak, že program prochází přesně rozlišitelnými stavy
uspořádaná pětice A = (S, Σ, σ, s, F)
S - konečná množina stavů automatu
∑ - konečná abeceda (množina vstupních symbolů)
σ - přechodová funkce – popisuje, do jakého stavu se automat přepne při vstupu dalšího vstupního symbolu
s ∈ S
- počáteční stav automatu
F ⊆ S
- množina koncových stavů
Gramatiky
pojmy
abeceda
- množina terminálních symbolů
gramatika
matematická struktura obsahující pravidla pro generování správných vět jazyka
obsahuje: non-terminální a terminální symboly, pravidla a počáteční non-terminál
G = (N, ∑, P, S) - uspořádaná čtveřice
- N - non-terminální symboly
- ∑ - terminální symboly (abeceda)
- P - pravidla
- S - počáteční non-terminál
symboly
- terminální - koncové, nereprezentují nic dalšího
- non-terminální - zkratky pro další syntaktické diagramy
gramatické pravidlo
přepisovací pravidlo (zkráceně pravidlo)
Slouží pro generování vět jazyka LG
- zapisují se ve tvaru α → β
- α, β jsou řetězce tvořené abecedou N ∪ Σ
- α je levá část pravidla, nesmí to být prázdný řetězec
- β je pravá část pravidla
vztah mezi jazykem, gramatikou a konečným automatem
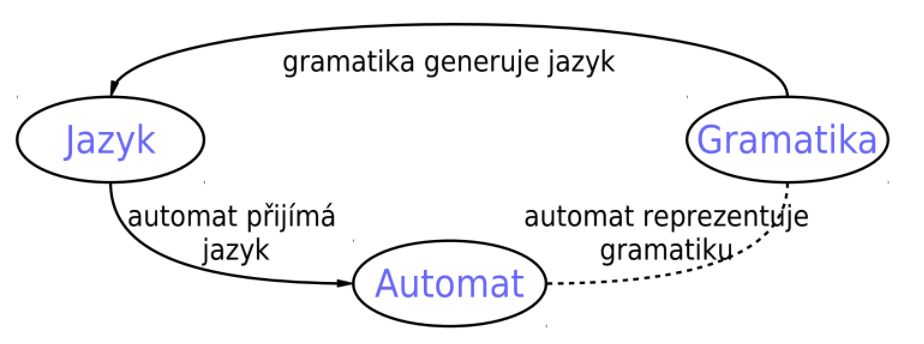
Chomského hierarchie gramatik

- regulární - non-terminál přepisuje na terminál, nebo na kombinaci non-terminálu a terminálu
- bezkontextové - non-terminál přepisuje na kombinaci jednoho nebo více terminálů a non-terminálů
- kontextové - jak bezkontextové, jen záleží na znacích před a po
- neomezené - libovolné přepisování (cokoliv můžeme přepsat na cokoliv)
Model počítače, strojové jazyky
Struktura a funkce procesoru: registry, řadič, ALU
struktura CPU
procesor
řadič
- řídící jednotka
- řídí činnost všech modulů CPU pomocí řídících signálů (moduly nazpět posílají stavová hlášení)
ALU (aritmeticko-logická jednotka)
- provádí veškeré aritmetické a logické operace
- obsahuje sčítačky, násobičky a komparátory
registry
- nejnižší a nejrychlejší úroveň paměti počítače
- obsahují operandy instrukcí
- po vykonání instrukce se do nich zapisují výsledky
- existují různé druhy (univerzální, specializované, matematické, vektorové, …)
von Neumannovo schéma, Harvardská architektura
von Neumannovo schéma
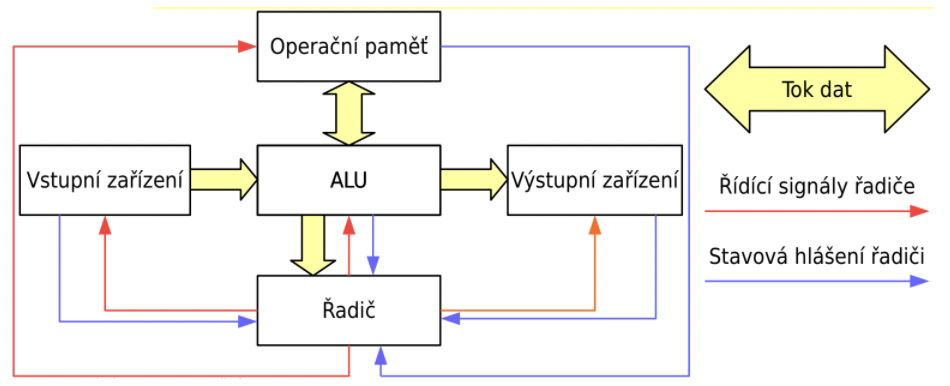
Harvardská architektura
- oddělené paměti programu a dat
- instrukce i data lze zpracovávat paralelně
- využití: např.: jednoúčelové počítače
instrukční cyklus
program řídí řadič mikroprocesoru takto
- převzetí instrukce z operační paměti
- dekódování instrukce
- provedení operace
- příprava k převzetí další instrukce
jazyk symbolických adres, assembler
jazyk symbolických adres (JSI)
- textová reprezentace strojového kódu
- nejnižší programovací člověk použitelný člověkem
assembler
- program pro překlad JSI do strojového kódu
metody adresování paměti
INSTRUKCE operand1, operand2operand
- přímý operand (konstanta)
- registr
- adresa paměťové buňky
- přímý operand - operand umístěn přímo v instrukci
- přímé adresování - operand je určen pomocí absolutní adresy paměťového místa
- registr - operandem je registr
- relativní adresování - adresa = bázový registr + relativní posun
- stránkové adresování - relativní adresování se segmentovým registrem
- indexové adresování - adresování s indexovým registrem
- nepřímé adresování - paměťové místo určené předchozími metodami obsahuje nikoliv operand, ale adresu
model paměti
3 sekce
heap space
- je dynamická
- po alokaci lze doalokovat další část
- přístup pouze skrz pointery
stack memory
- je statická
- po alokaci nelze zvětšit
- přístup přímo (skrz hodnoty proměnných)
- dealokuje se po skončení bloku (nemusí se čistit)
code section
- zavedená při načtení souboru
- obsahuje instrukce pro vykonání algoritmu

Dynamické datové struktury
pojem abstraktní datový typ
výraz pro typy dat, které jsou nezávislé na vlastní implementaci
definován názvem, množinou hodnot a množinou operací, které je možno vykonat
umožňuje vytvářet i složitější datové typy (např. zásobník, fronta a asociativní pole)
zjednodušuje a zpřehledňuje programy
datový typ ukazatel
neobsahuje data, pouze adresu na místo v paměti
dynamická datová struktura
- mění svou velikost během života programu
- tvořena prvky stejného typu
- prvek - struktura, obsahuje ukazatel na (alespoň na jeden) další prvek (poslední má ukazatel na
NULL)
Konstrukce základních dynamických datových struktur a operace s nimi
zásobník - LIFO
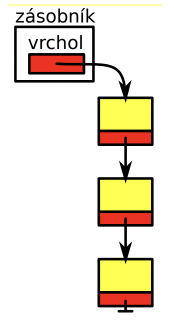
- tvořen jednosměrně vázaným seznamem prvků
- počáteční prvek - vrchol (top)
- LIFO - last-in-first-out, otáčí pořadí prvků
- operace: push, pop
fronta - FIFO
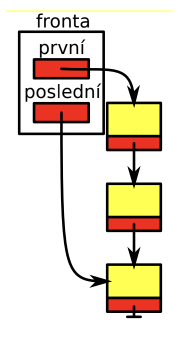
- tvořen jednosměrně vázaným seznamem prvků
- vytváří buffer (odkládání prvků pro pozdější zpracování ve stejném pořadí)
- FIFO - first-in-first-out, zachová pořadí prvků
- operace: enqueue, dequeue
seznam
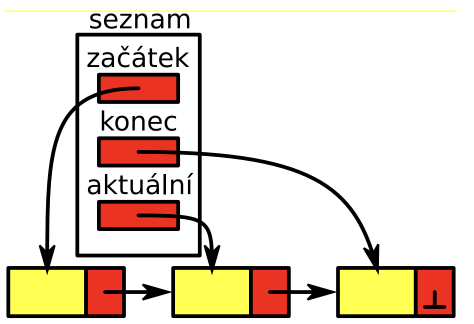
- řada vzájemně provázaných prvků
- má “čtecí hlavu”, pamatuje si nad kterým prvek proběhla poslední operace
- homogenní, lineární, sekvenční, dynamická struktura
- prvky lze vkládat a odebírat uprostřed seznamu
- může být obousměrný
- kruhový seznam = poslední prvek ukazuje na první
- operace: (zásobníku a fronty) + insert, removeNext, prev (posune aktuální prvek na předchozí)
binární vyhledávací strom
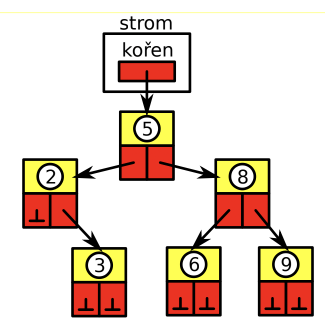
pro rychlé ukládání a vyhledávání podle klíče
strukturovaná data = párové hodnoty: klíč + hodnota
- uzel stromu - obsahuje ukazatel na levý a pravý podstrom, nese hodnotu klíče a data asociovaná s klíčem
binární strom - ukazatel na kořenový uzel
vlastnosti:
- výška stromu - délka nejdelší cestu od kořene
- váha stromu - počet uzlů stromu
- vyvážený strom - po všechny uzly platí, že váha jejich podstromů se liší maximálně o jedničku
operace:
průchody stromem
- inorder -
inorder(levý); akceSAktuálnímUzlem(); inorder(pravý); - preorder -
akceSAktuálnímUzlem(); preorder(levý); preorder(pravý); - postorder -
postorder(levý); postorder(pravý); akceSAktuálnímUzlem();
- inorder -
přidání
odebrání
vyhledání uzlu
Hromadné zpracování dat, databáze
Proč HZD? Úlohy HZD
důvodem jsou velká data (dva problémy - ukládání a zpracování)
úlohy HZD:
řazení - usnadňuje hledání
fyzické řazení - při řazení podle různých klíčů vznikají kopie
souborů
indexové soubory - obsahují odkazy na kmenový soubor řadí se
indexy, zabírají méně místa => může existovat více indexových
souborů seřazených podle jiných klíčů
výběr - hledání, zobrazení (např.: SQL databáze)
aktualizace - úprava existujícího záznamu, přidání, odstranění
interaktivní - změny se provádí přímo do souboru (při velkém
množství příliš pomalé)
dávková - rozdělení na kmenový soubor a soubor změn, je
potřeba aktualizační program, který se za určitý čas spustí a aplikuje změny do původního souboru (plynulejší, možnost stornovat)
konverze - převody mezi formáty dat
- formuláře - interaktivní rozhraní pro vkládání dat uživatelem
- sestavy - přehledně formátované výsledky dotazů (např.: stránka reprezentující nákupní košík)
Organizace souborů z pro hromadné zpracování dat (tj. obrovské soubory), přístup k souborům
organizace souborů
vkládání záznamů do seřazené souboru
řešení: oblast přeplnění + dávkové zpracování
oblast přeplnění
- neseřazená část na konci souboru, kam se vkládají nové soubory
- do seřazené se zařadí jednou za čas aktualizačním
vyhledávání probíha ve dvou krocích:
- rychlé vyhledávání v seřazené části
- sekvenční vyhledávání s oblasti přeplnění
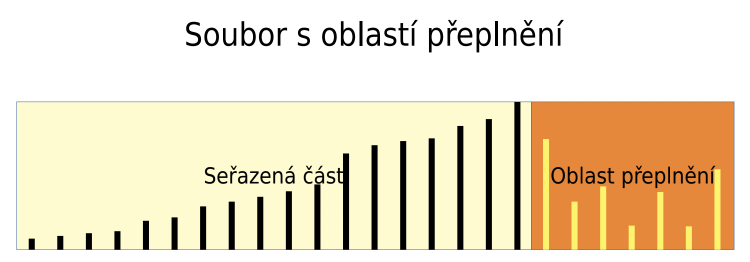
odstranění
řešení: změna příznaku v záznamu
logická položka - příznak aktivního/smazaného prvku
ostatní operace ignorují záznamy s příznakem smazaného prvku
fyzické odstranění provede až aktualizační program

přístup k souborům
sekvenční soubory
- neseřazené - jednoduchá implementace, pomalé
- seřazené - možnost použít rychlejší algoritmy
soubory s přímým přístupem
- jako u polí - dostat se k libovolnému prvku trvá stejně dlouho
- fyzicky jen na specifickém hardware
index-sekvenční přístup
- data rozdělena na bloky
- blok lze vyhledat rychle, přímým přístupem
- v rámci bloku se vyhledává sekvenčně
- princip kartotéky - šuplíky podle abecedy
- hašovací tabulka s kolizemi - kolize tvoří bloky, které je třeba prohledávat sekvenčně
indexový soubor
kmenový soubor - nemusí být řazený
indexový soubor
- pomocný soubor s odkazy na záznamy v kmenovém souboru
- je seřazený podle vybraného klíče (čteného z kmenového souboru)
- může jich existovat víc pro jeden kmenový soubor
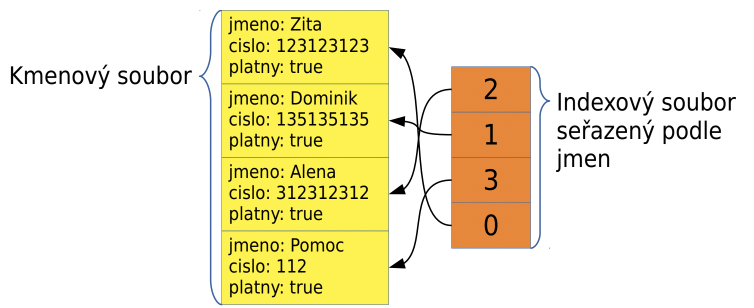
- výhody: řeší problémy s vyhledáváním podle různých klíču
- nevýhody: zabírá místo navíc
Součásti databáze
součásti
databáze (DB)
množina logicky uspořádaných dat
relační databáze
data uložena v tabulkách
řádek tabulky = záznam = popis jedné konkrétní entity reálného světa
tabulka je složená z entit, které mají své atributy
vztahy = relace
pomocí struktury tabulek a odkazy mezi záznamy
realizovány pomocí primárních a cizích klíčů
primární klíč
- jednoznačně identifikuje záznam
- musí být jedinečný a neprázdný
- jednoduchý (jeden atribut) ✖️ složený (množina atributů)
cizí klíč
- odkaz na jiný záznam v téže nebo jiné tabulce
- obsahuje hodnotu primárního klíče odkazovaného záznamu
systém řízení báze dat (SŘBD)
část DBS pro manipulaci a přístup k datům
obsahuje interpret jazyka pro:
- definici databáze
- manipulaci s daty
pojmy:
- entita = rozlišitelný, jednoznačně identifikovatelný objekt reálného světa, který chceme ukládat do DB (jeden záznam/řádek)
- entitní množina = množina entit téhož typu (tabulka)
- atribut = vlastnosti entity
- kardinalita = počet vztahů, ve kterých se může entita vyskytovat (1:1, 1:N, M:N)
- formuláře - interaktivní rozhraní pro vkládání dat uživatelem
- sestavy - přehledně formátované výsledky dotazů (např.: stránka reprezentující nákupní košík)
Eliminační metody pro řešení soustav n lineárních rovnic o n neznámých
pojmy
numerická metoda
algoritmus popisující cestu k řešení numerické úlohy
používá se, když je analytické řešení složité, nebo náročné
řešení soustav lineárních rovnic:
eliminační metody
- analytický algoritmický postup
- pracuje s absolutní přesnosti
iterační metody
- aproximační algoritmický postup
- pracují se zvolenou přesností (čím déle počítají, tím přesnější jsou)
prostředky:
- interpolace (nalezení přibližné hodnoty spojením známých bodů)
- derivace
- aproximace (odhad, často funkce)
- integrace
přesnost - přesnost výpočtů bude tak přesná, jako je přesnost výpočtů na počítači (vždy dojde k nějakému danému zaokrouhlení)
vyjádření soustavy lineárních rovnic pomocí matic
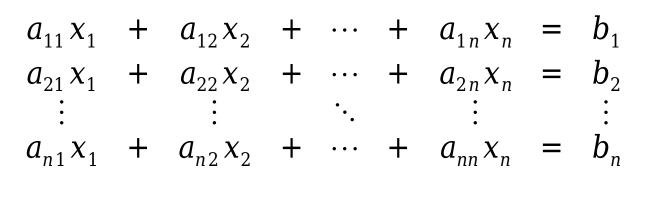
- řádky matice představují jednotlivé rovnice
- sloupce jednotlivé koeficienty
Gaussova eliminační metoda
používá ekvivalentní úpravy nad rozšířenou maticí soustavy
eliminuje neznámé pod hlavní diagonálou - horní trojúhelníková matice soustavy
algoritmus:
- přímý chod - převod rozšířené matice do tvaru horní trojúhelníkové matice za pomocí ekvivalentních řádkových úprav
- test řešitelnosti - má-li soustava 0 nebo ∞ řešení, skonči
- zpětný chod
pivotování - popřehazování řádků tak, aby v každém sloupci byla v absolutní hodnotě největší hodnotou na hlavní diagonále (ve sloupci hledám na hlavní diagonále a pod ní)
výhody
- paralelizace
- lze aplikovat na rozsáhlé matice
- konvergence je u diagonálně dominantních funkcí zaručena nevýhody
- pomalejší
Gauss-Jordanova eliminační metoda
- upravena GEM, nuluje se pod i nad hlavní diagonálou
- vytváří jednotkovou matici soustavy, tudíž odpadá zpětný chod
- nelze paralelizovat
Iterační metody pro řešení soustav n lineárních rovnic o n neznámých
pojmy
numerická metoda
- algoritmus popisující cestu k řešení numerické úlohy
- používá se, když je analytické řešení složité, nebo náročné
přesnost
- přesnost výpočtů bude tak přesná, jako je přesnost výpočtů na počítači (vždy dojde k nějakému danému zaokrouhlení)
- u iteračních metod se přesnost výsledků zvyšuje s časem/počtem opakování
konvergence
- prvky řady se musí blížit k cílové hodnotě
 se od určitého bodu i musí limitně blížit nule
se od určitého bodu i musí limitně blížit nule- matice je diagonálně dominantní = zaručená konvergence
- opakem je divergence
stabilita
- malé změny vstupních dat způsobí jen malé změny výstupních dat
iterační výpočet
rekurentní vztah
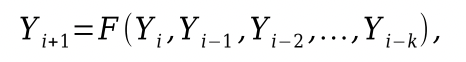
- pro výpočet další hodnoty potřebujeme
k+1předchozích hodnot - člen posloupnosti je určen předchozími členy posloupnosti
- pro výpočet další hodnoty potřebujeme
algoritmické schéma výpočtu podle rekurentního vztahu
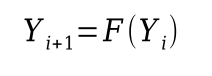
- Y = y0
- while (not B(Y)) Y = F(Y)
- Y - proměnná
- B - predikát (podmínka požadované hodnoty závislá na přechozím výsledku Y)
- F - funkční symbol
Jacobiho iterační metoda
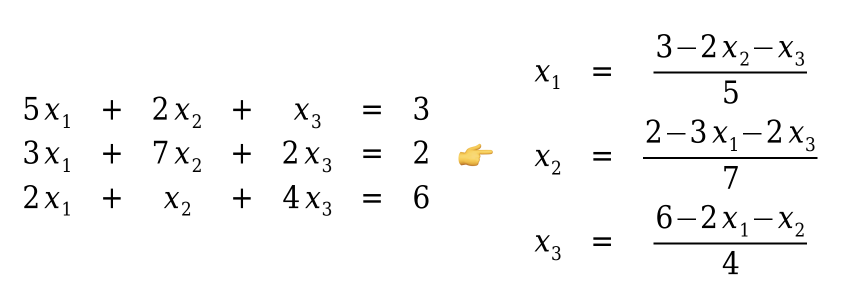
- začnu s polem neznámých x, které inicializuji na nulu
- neznámé x si v každé iteraci vypočítám a jejich nové hodnoty zapíšu do pole nových hodnot
- na konci iterace si pole neznámých x přepíšu polem nových hodnot
- opakuju, dokud rozdíl hodnot všech neznámých x mezi poli starých a nových hodnot není menší, jak daná přesnost (𝛆)
Gauss-Seidelova iterační metoda
skoro stejná Jacobiho metoda, ale nově vypočítané hodnoty zapisuji rovnou do pole starých hodnot
porovnávám přesnost před zapsáním nové hodnoty do pole (předpoklad pozitivity v rámci jedné iterace; jestli najdu nepřesnost, tak je celá iterace nepřesná)
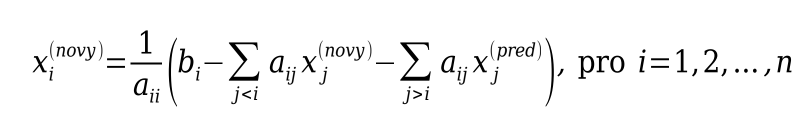
Řešení nelineárních rovnic
pojmy
přesnost
- přesnost výpočtů bude tak přesná, jako je přesnost výpočtů na počítači (vždy dojde k nějakému danému zaokrouhlení)
- u iteračních metod se přesnost výsledků zvyšuje s časem/počtem opakování
konvergence
- prvky řady se musí blížit k cílové hodnotě
- se od určitého bodu i musí limitně blížit nule
- opakem je divergence
vyčíslení polynomu Hornerovým schématem
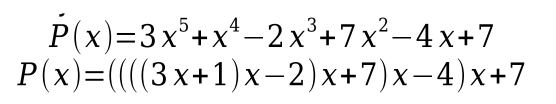
operace: násobení, sčítání
časová složitost: O(n)
používá se na vyčíslení polynomů

definice úlohy řešení nelineárních rovnic
- hledáme řešení rovnice
P(x) = 0, kde P je polynom - pro funkci
f(x)hledáme hodnotu a takovou, žef(a) = 0
metody
metoda půlení intervalů

v každém kroku se chyba aproximace sníží dvakrát
výhody:
- obecná, robustní metoda
- při splnění podmínek zaručeně konverguje (v případě více kořenů v intervalu najde jeden z nich)
nevýhody:
- relativně pomalá
- hrozí ztráta přesnosti kvůli zaokrouhlovacím chybám
metoda tětiv (regula falsi)
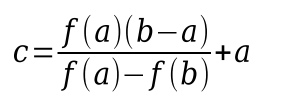
výhody:
- vždy konverguje
- obvykle rychlejší než půlení intervalů
nevýhody:
- stejné, jako u půlení intervalů, jen menší
metoda sečen
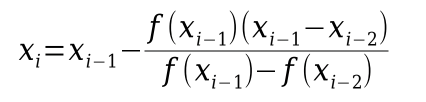
newtonova metoda
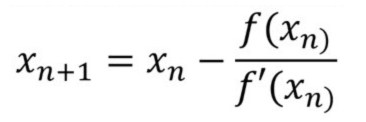
Metoda nejmenších čtverců
pojmy
aproximace
- funkce, která se nejvíce blíží naměřeným hodnotám
interpolace
- funkce, která prochází všemi naměřenými body
princip
součet vzdáleností od bodů je lineární funkce a nemá minimum, proto součet čtverců kvadratická funkce a navíc snadno derivovatelná
postup:
- dosazení bodů, suma
- parciální derivace podle a a b
- minimum má tečnu rovnoběžnou s osou x (směrnice = 0 👉 derivace = 0)
- řešení dvou rovnic o dvou neznámých
odvození pro konstantní a lineární funkci
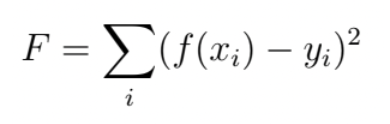
liší se tím, co dosadím za f()
- konstantní -
f: y = b - lineární -
f: y = a*x + b
- konstantní -
Metody vnitřního řazení
vlastnosti řadících algoritmů
časová složitost -
T(n)funkce závislá na rozměru řešené úlohy
n - rozměr úlohy (např.: počet prvků řazeného pole)
výsledkem je počet elementárních kroků algoritmu
odhad časové složitosti -
O(T(n))- založený na nejrychleji rostoucí části vzorce
prostorová složitost
- funkce závislá na rozměru řešené úlohy
- udává počet paměťových buněk potřebných pro výpočet
- in situ - “na místě,” nevyžaduje prostor pro kopii všech vstupních dat
přirozenost
Řadící algoritmus je přirozený, pokud platí, že čas pro řazení seřazených dat je menší než čas pro řazení náhodně uspořádaných dat a ten je menší než čas pro řazení opačně seřazených dat.
stabilita
Řadící algoritmus je sekvenční, pokud k prvkům přistupuje sekvenčně, tj. navštěvuje vždy jen vedlejší prvky (následující nebo předchozí) a neskáče doprostřed řazeného pole.
algoritmy
Insertion sort
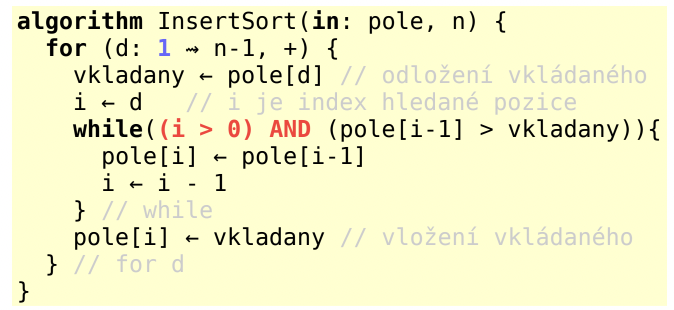
se zarážkou
optimalizace procesu vkládání
vyrobím pole o jeden prvek delší a na pozici nula vložím vkládaný prvek (data tudíž začínají na indexu 1)

O(n2), je přirozený, je sekvenční, je stabilní, prostorová složitost - lineární, in situ
Selection sort

- O(n2), není přirozený, je sekvenční, není stabilní, prostorová složitost - lineární, in situ
Bubble sort

s pamětí poslední výměny - Ripple sort
- dělící čáru posune na index poslední výměny
- na seřazeném poli stačí jeden průchod
Shaker sort
- dva vnitřní cykly - jeden posouvá minimum doleva, druhý posouvá maximum doprava
O(n2), základní verze není přirozená, je sekvenční, je stabilní, prostorová složitost - lineární, in situ
princip ostatních metod
Merge sort
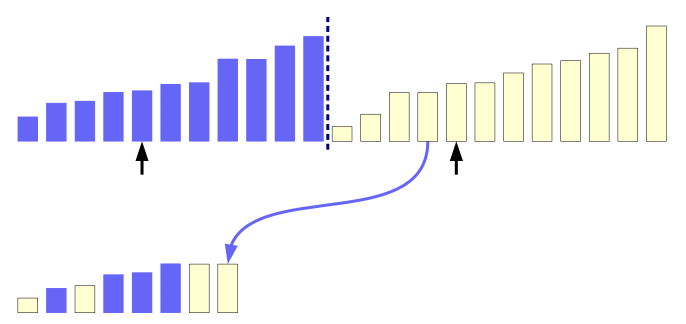
- O(n*log n) - průměrná i nejhorší, není přirozený, je sekvenční, je stabilní, prostorová složitost - OS(n), není in situ
Quick sort

pivot
- ideálně medián, ale ten je obtížné najít
- jeho výběr dramaticky mění časovou složitost algoritmu
dělení DNF - Dutch National Flag
pole rozděleno na tři části
- prvky menší, jak pivot
- prvky stejně velké, jak pivot
- prvky větší, jak pivot
O(n*log n) - pro průměrný případ, přirozenost závisí na dělení a výběru pivota, jde udělat sekvenční (ale zde není), není stabilní, prostorová složitost - OS(log n)
Metody vnitřní řazení
specifika vnějšího řazení
data ve vnější paměti
sekvenční zpracování
pro data, která se nevejdou do paměti, tudíž nejde použít vnitřní řazení
pomalejší, než vnitřní řazení
princip: přesouvání řazených prvků mezi sekvenčními soubory na disku
Xpáskové
- pracují s určitým počtem souborů/pásek
- vyžadují pomocné soubory/pásky
Yfázové
- řazení rozděleno do několika fází
pojmy
- fáze - operace, při které se manipuluje s celou množinou dat (např.: rozdělovací fáze)
- krok algoritmu - nejmenší podproces, jehož opakování se realizuje řazení
přímé a přirozené řazení
přímé slučování
3pásková, 2fázová metoda
1 vstupní páska a 2 pomocné pásky
krok je rozdělen do 2 fází
rozdělovací fáze
- rozděluju vždy na 2x větší části, jak v předchozím kroku
slučovací fáze
- jedu po pomocných páskách a vždy na hlavní pásku zapíšu menší číslo, na té pásce se posunu dál a znovu porovnávám

přirozené slučování
- jako přímé, jen místo úseků pracuje s běhy
- běh = nejdelší seřazený úsek
metody zlepšování
vyvážené slučování
- 4pásková, 2fázová metoda
- přidáním jedné pásky (částečně) eliminuje rozdělovací fázi
vícepáskové slučování (vícecestné vyvážené slučování)
n pásek, kde n je sudé číslo
n/2cestné, jednofázové slučování
- v každém kroku n/2 vstupních a n/2 výstupních pásek
princip polyfázového slučování
- rozděl běhy do n-1 pásek tak, aby počtem odpovídaly Fibonacciho posloupnosti
- dokud není nejkratší páska prázdná, slučuj běhy na výstupní pásku
- přepni pásky - výstupní se přepne na vstupní a prázdná na výstupní
- opakuj, dokud nejsou vstupní pásky prázdné
Vyhledávací algoritmy
pojmy
klíč
- údaj podle kterého hledáme
- jednoduchý - jedna ze složek struktury
- složený - více složek struktury
sekvenční vyhledávání
v neseřazeném poli
sekvenční procházení prvků datové struktury dokud nenaleznu shodu nebo nedojdu na konec
- pomalé, ale některé údaje nejde seřadit
v seřazeném poli
- stejné jako v neseřazeném poli, ale skončím i když najdu větší klíč (protože za ním už je zpravidla nemůže vyskytnout hledaný klíč)
s zarážkou
- ne konec pole dám zarážku, kterou nastavím na můj hledaný klíč
- nemusím sledovat, jestli jsem na konci pole - když najdu, co jsem hledal, zjistím, jestli jsem našel zarážku nebo ne
binární vyhledávání
vyžaduje seřazené pole
intuitivní princip “hledání ve slovníku”
princip:
hledám v daném intervalu
podívám se na prostřední prvek v intervalu
- pokud je shodný s hledaným klíčem, našel jsem hledaný prvek a algoritmus končí
rekurzivně se zanořím do jedné z polovin v závislosti na porovnávání hledaného klíče se středovým prvkem intervalu
má-li interval délku jedna není v něm hledaný klíč, pole hledaný klíč neobsahuje
nejrychlejší algoritmus nad seřazeným polem, O(log2 n)
nefunguje v neseřazeném poli
hašovací tabulka
klíče jsou pomocí hašovací funkce přepočítány na indexy v poli)
hašovací funkce
- matematická funkce:
hash(obrovské číslo) -> malé čislo - nemá inverzní funkci (použití v kryptografii)
- matematická funkce:
v ideálním případě je jednoznačná - neexistuje stejný hash pro různé klíče
je obtížné mít spolehlivou hašovací funkci a je v praxi nedosažitelné nemít kolize
princip index-sekvenčního vyhledávání
- kvůli kolizím používáme hašovací tabulku pro identifikaci bloků a ty procházíme sekvenčně
binární vyhledávací strom
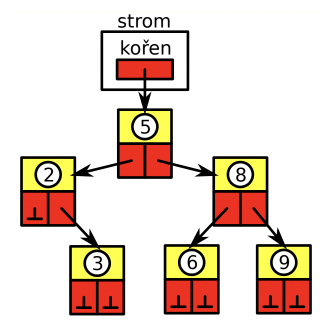
pro rychlé ukládání a vyhledávání podle klíče
strukturovaná data = párové hodnoty: klíč + hodnota
- uzel stromu - obsahuje ukazatel na levý a pravý podstrom, nese hodnotu klíče a data asociovaná s klíčem
binární strom - ukazatel na kořenový uzel
vlastnosti:
- výška stromu - délka nejdelší cestu od kořene
- váha stromu - počet uzlů stromu
- vyvážený strom - po všechny uzly platí, že váha jejich podstromů se liší maximálně o jedničku
operace:
průchody stromem
- inorder -
inorder(levý); akceSAktuálnímUzlem(); inorder(pravý); - preorder -
akceSAktuálnímUzlem(); preorder(levý); preorder(pravý); - postorder -
postorder(levý); postorder(pravý); akceSAktuálnímUzlem();
- inorder -
přidání
odebrání
vyhledání uzlu
srovnání vyhledávacích metod
sekvenční vyhledávání
výhody:
- nejobecnější algoritmus
- v některých případech jiný přístup není možný (nelze seřadit pole)
nevýhody:
- lineární časová složitost (O(n))
- hledání “hrubou silou,” neefektivní
se zarážkou
výhody:
- nemusí testovat konec pole -> rychlejší, ale ne o moc
nevýhody:
- je třeba udělat pole větší o jeden prvek
v seřazeném poli - rychlejší, ale je třeba pole napřed seřadit (pomalejší přidávání prvků)
binární vyhledávací strom
výhody:
- efektivní a rychlá metoda
nevýhody:
- na neseřazeném poli nefunguje
hašovací tabulka
výhody:
- rychlé a efektivní i co se týče úprav v poli
nevýhody:
- kolize a nereálnost dokonalé hašovací funkce
Objektově orientované programování
pojmy
třída
- popisuje stejný typ objektu
- modeluje vztah
předek - potomek
objekt
- konkrétní entita
- proměnná
atribut
- vlastnost objektu
- proměnná uvnitř objektu
metoda
- činnost/služba objektu
- podprogram popsaný v třídě
zapouzdření, dědičnost, polymorfismus
zapouzdření
- ukrývá informace uvnitř objektu
- z vnějšku objektu se k informacím dá dostat jen přes jeho rozhraní
dědičnost
- umožňuje snadné rozšiřování funkcionality tříd/objektů
polymorfismus
- umožňuje stejné zacházení s předky i potomky, i když se potomci chovají jinak
praktické použití OOP
- původně simulace a umělá inteligence
- kód je přidružen k datům
- vyšší bezpečnost programů
- přirozená modularita
- snaží se popisovat chování reálného světa pomocí termínů používaných v reálném světě
Operační systémy
struktura OS (vrstvy)
jádro (kernel)
- moduly pro přidělování prostředků, řízení procesů, …
systémové knihovny a programy
uživatelské rozhraní
- CLI - textové rozhraní
- GUI - grafické rozhraní
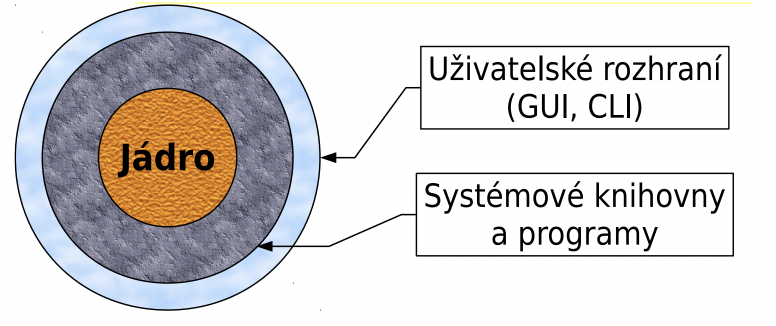
modulární OS
moduly zefektivňují vývoj operačního systému
monolitické jádro
- jádro je kompaktní program
- moduly na úrovni zdrojového kódu
- po sestavení vzniká kompaktní binární program - jádro
mikrojádro
- malé základní jádro běžící v chráněném režimu
- moduly - servery, které obsluhují nekritické služby systému
- např.: Hurd
základní moduly:
modul přidělování paměti
- udržuje údaje o stavu paměti
- přiděluje paměť procesům, co si o ni požádají (např.: malloc())
- uvolňuje paměť procesům, co se ji vzdají (např.: free())
modul přidělování procesoru
vyžaduje privilegovaný režim procesoru
plánovač úloh
- rozhoduje o přepínání procesů
- rozhoduje o časových úsecích přiřazených procesu
- bere v úvahu priority procesů
modul správy periferií
- sleduje stav periferie - dispečer
- spooler - realizuje frontu požadavků (např.: úloh pro tiskárnu)
modul správy souborů
sleduje stav souborů
rozhoduje
- o přístupů procesů k souborům na základě jejich práv
přiděluje soubor pro použití (otevření souboru)
vyžaduje vrácení souboru (zavření)
multitasking
metoda přepínání procesů tak, aby se zdálo, že běží současně
- výměna vykonávaných procesů - přepnutí kontextu
kooperativní
- procesy se samy na chvíli vzdají procesoru
- nebezpečné kvůli “chamtivým” procesům
preemptivní
- jádro vynucuje přerušení procesů
- musí mít podporu v HW (procesoru)
- složitější, ale bezpečnější
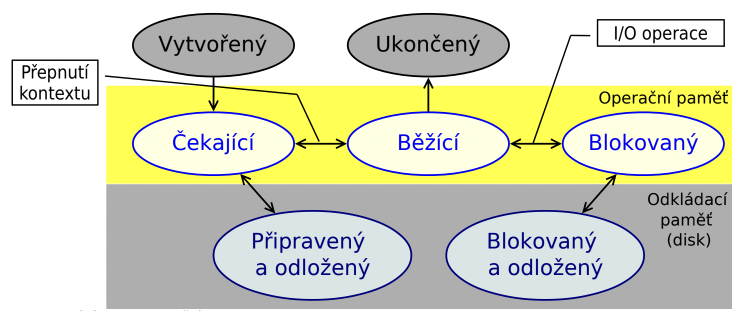
procesy, vlákna, životní cyklus procesu
procesy
- výpočet, který lze provádět paralelně s ostatními výpočty
- spuštěny počítačový program
- vytváří jej, je řízen a spravován operačním systémem
- může se dělit na vlákna
vlákna
- odlehčené procesy
- sdílejí paměť procesu
- nutnost řešit synchronizaci
životní cyklus procesu
Počítačové sítě - hardware
rozdělení sítí
spojové
- uzly a aktivní prvky nejprve dohodnou pevnou cestu mezi dvěma počítači
- typické pro telefonní sítě
nespojové
- data rozdělena na pakety
- o cestě paketu rozhodují jednotlivé uzly sami - přepojování paketů
- typické pro počítačové sítě (LAN)
druhy sítí
podle rozsahu
PAN - personal area network
- osobní, domácí síť
- obvykle wi-fi + kabeláž
LAN - local area network
- lokální, homogenní sítě tvořené PC
- obvykle kabeláž + wifi
- např.: firma, škola
MAN - metropolitan area network
- regionální/městská síť
- propojuje menší sítě v regionu
- obvykle kabeláž v kolektorech (drát, optika)
WAN - wide area network
- rozlehlé sítě - sítě sítí - národní, celosvětový rozsah
- páteřní sítě
- Internet, u nás CESNET
podle řízení
klient - server
hierarchické sítě s vyhrazenými servery
- centralizované uložení dat - zamezuje redundanci dat
peer to peer
- žádná hierarchie, všechny počítače jsou si rovny
- především pro sdílení dat
- decentralizované
topologie
charakterizuje způsob propojení jednotlivých uzlů sítě
- skutečná - fyzická podoba
- logická - virtuální podoba
kruh (ring)
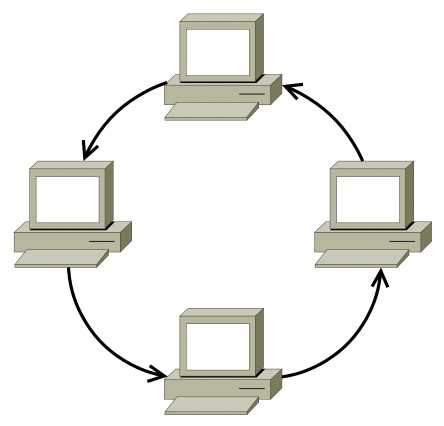
každý počítač je propojen se dvěma sousedy
pakety se posílají jedním směrem
vždy vysílá jen jeden počítač, ostatní posílají a přeposílají
token ring
- princip předávání práva vysílat (tokenu)
sběrnice (bus)
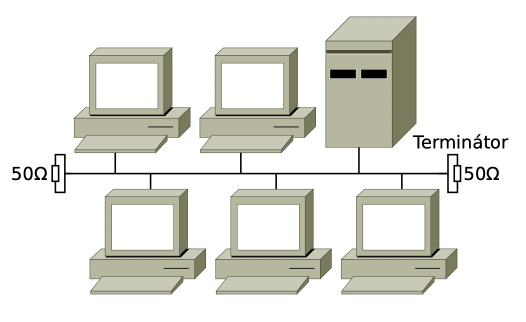
počítače připojeny k průběžnému vedení
vyslaná zpráva se šíří všemi směry, na konci vedení je pohlcena koncovkou (rezistorem)
realizována pomocí koaxiálních kabelů
kolize
- když vysílají dvě stanice zároveň, dochází k rušení signálu
- řešením je například metoda token bus nebo metoda přístupu CSMA/CD
hvězda
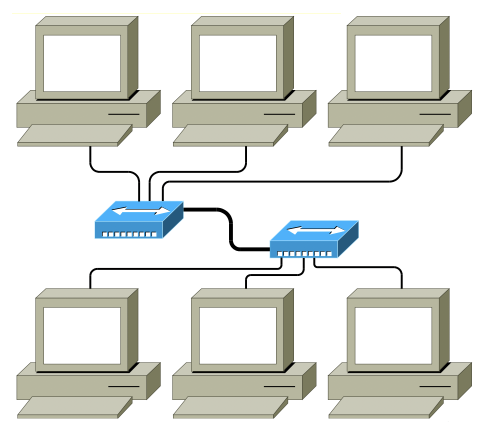
- stanice jsou připojeny na rozbočovač (hub, propojovací centrum)
- vyslaná stanice se šíří celou sítí, cílová stanice ji přijme
- použití přepínače (switch) místo rozbočovače 👉 zpráva míří rovnou k adresátovi, ne k ostatním
- dnes u LAN nejčastější
kombinované
prvky sítě
pasivní
aktivní
opakovač (repeater)
- zesiluje a obnovuje signál
rozbočovač (hub)
- umožňuje rozvětvení sítě
- dnes nahrazeno přepínačem
přepínač (switch)
- inteligentní propojovací prvek pro hvězdicovou topologii
- pracuje s MAC adresami zařízení
most (bridge)
- odděluje segmenty sítě a tím zmenšuje zátěž
- levnější, než router
směrovač (router)
- propojuje lokální sítě používající stejný komunikační protokol
- směruje data mezi sítěmi pomocí IP adres
- obvykle optimalizovaný počítač
brána (gateway)
- nejvýše postavený aktivní prvek v sítích
- spojuje sítě s různými komunikačními protokoly
- plní i práci routeru
metody přístupu
token ring
- kruhová topologie, kde vysílá a přijímá jen stanice, která má zrovna token
token bus
- sběrnicová topologie, kde vysílá a přijímá jen stanice, která má zrovna token
CSMA/CD
- pokud volné, vysílá
- dokud vysílá, poslouchá, jestli něco nepřichází
- pokud došlo ke kolizi, přenos se ukončí a pokusí se ho provést znovu
funkce počítačové sítě
- sdílení
- přenos
- ochrana dat
- komunikace (email, chat, …)
- vzdálená práce (ssh, …)
Počítačové sítě - software
model ISO/OSI
OSI - Open System Interconnection
vrstvy (7):
- aplikační - aplikace poskytující síťové služby uživateli
- prezentační - konverze dat (která mohou bát jinak kódována), často splývá s relační vrstvou
- relační - navazuje, udržuje a synchronizuje spojení mezi uživateli
- transportní - dělí pakety podle transportního protokolu, přijaté pakety skládá do zpráv
- síťová - přiřazuje adresy, volí trasu paketu - routing
- linková - stará se o přenos mezi dvěma fyzickými uzly, jeho bezchybnost
- fyzická - popisuje fyzické vlastnosti přenosového média
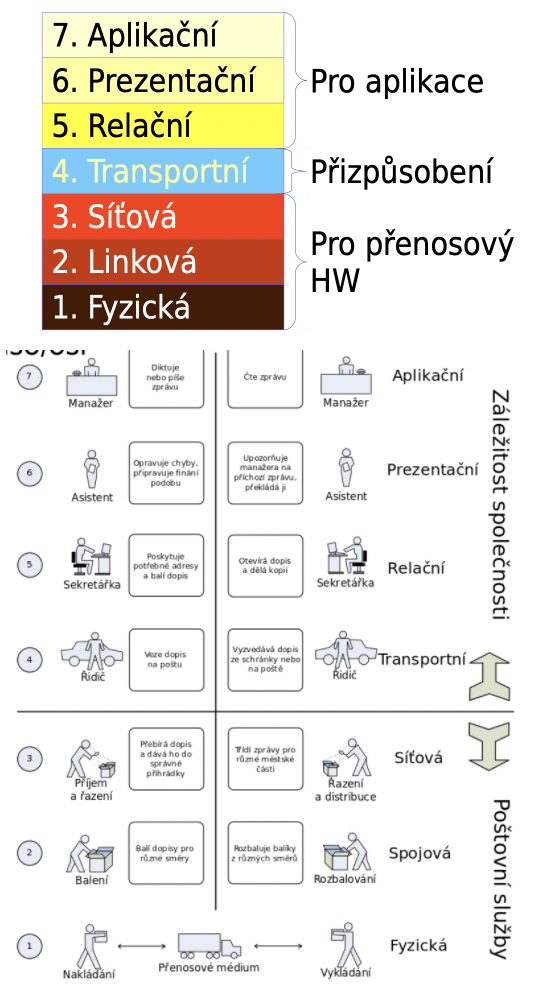
- model komunikace v počítačové síti
princip komunikace
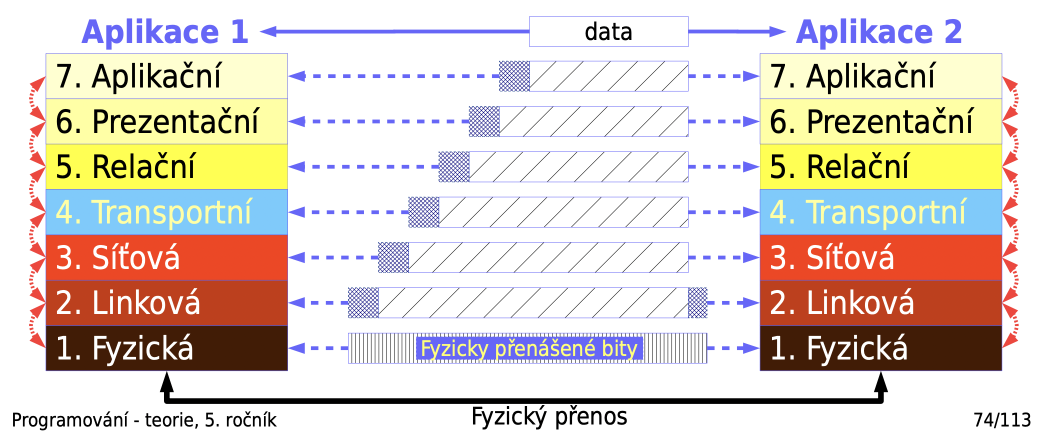
každá vrstva přidává k datům další údaje
- SDU - Service Data Unit, užitečná data dané vrstvy
- PCI - Protocol Control Information, řídící informace dané vrstvy
- PDU - Protocol Data Unit,
= SDU + PCI
mezi vrstvami
- komunikují spolu vždy stejné vrstvy
mezi uzly sítě
- vysílací uzel - vyšší vrstva předává data nižší vrstvě
- přijímací uzel - nižší vrstva předává data vyšší vrstvě
model TCP/IP
zjednodušení modelu ISO/OSI
vrstvy (4):
vrstva síťového rozhraní
- přístup a definice fyzického rozhraní
- specifická pro každou implementaci sítě
- např.: Ethernet, Token Ring, …
síťová vrstva
- zajišťuje adresaci, směrování a předávání datagramů
- realizovaná ve všech prvcích sítě
- např.: IP protokol, …
transportní vrstva
- poskytuje spojení spolehlivým (TCP) nebo nespolehlivým (UDP) protokolem
- realizovaná až v síťových kartách (koncových zařízeních)
aplikační vrstva
- programy, které realizují konkrétní služby pro uživatele
- spojení je určeno číslem portu
- port - dohodnuté číslo přiřazené zvenčí aplikaci operačním systémem
- např.: HTTP, FTP, DHCP, …
model přenášených dat
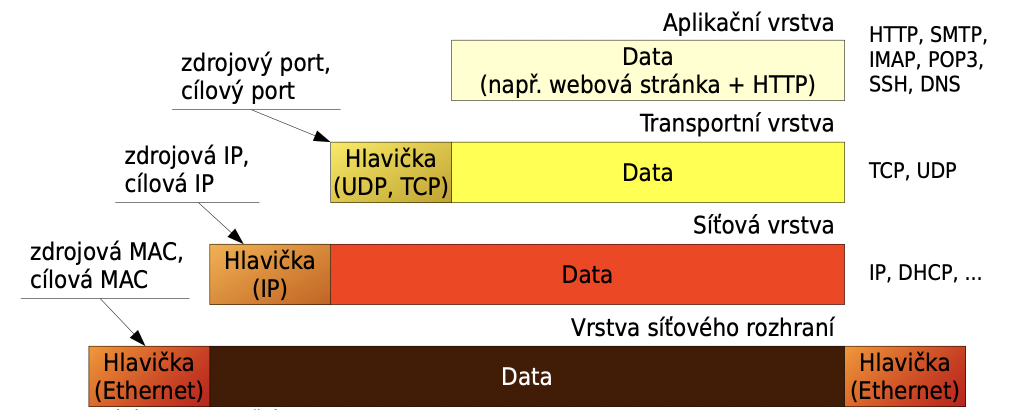
metody adresování
MAC
- fyzická adresa
- celosvětově jedinečný identifikátor
IP
- určuje klienta serveru
DNS
- distribuovaná databáze názvů hostitelských domén a jejich IP adres
- tabulky jsou uloženy na směrovačích, přepínačích a branách různých vrstev internetu
protokoly
definice
- soubor pravidel pro komunikaci mezi 2 a více body
TCP/IP
- rodina protokolů
- 4 vrstvy
IP - Internet Protocol
- vysílá a přijímá datagramy
- poskytuje nespojové síťové spojení
- nespolehlivé, spolehlivost zaručují vyšší vrstvy
TCP - Transmission Control Protocol
spojový a spolehlivý přenos dat
fáze: navázání spojení, přenos dat, ukončení spojení
paket
- základní jednotka přenosu dat nespojových sítí se spolehlivým přenosem
- ve 4. vrstvě
UDP - User Datagram Protocol
poskytuje nespolehlivou transportní službu pro aplikace, které spolehlivost nepotřebují
fáze: přenos dat
datagram
- základní jednotka přenosu dat nespojových sítí s nespolehlivým přenosem
internet
vymezení
- celosvětová sít komunikace
- organizovaná skrze protokol TCP/IP
struktura
- propojené malé sítě
adresování mezi uzly v internetu
- komunikaci mezi sítěmi zajišťují gateway
- pro lepší orientaci byla zavedena služba DNS, která se stará o domény a překlad IP adres do pro lidi stravitelného formátu
Booleova algebra a její využití
základní pojmy
logická hodnota
- hodnoty, jichž mohou nabývat logické proměnné
logická proměnná
- nabývá právě dvou jasně rozlišitelných hodnot
- v logickém obvodě reprezentuje fyzikální veličinu
logická funkce
- obecně funkce - zobrazení, která n-tici nezávislých logických proměnných xi zobrazuje na m-tici stavů závisle proměnných yi
logický obvod
- fyzikální obvod, v němž každá vstupní, výstupní či vnitřní fyzikální veličina nabývá v ustáleném stavu pouze dvou, jasně odlišitelných, diskrétních hodnot
- typy: kombinační, sekvenční
logický člen (hradlo)
- elementární zařízení, které realizuje elementární logické funkce v číslicových počítačích nebo jiných číslicových zařázeních
- např.: logický součin AND
logické funkce
základní:
- součet (OR)
- součin (AND)
- negace (NOT)
- exkluzivní součet (XOR)
- negovaný součin (NAND)
- negovaný součet (NOR)
logické výrazy
- sestavují se z logických proměnných a konstant pomocí základních logických operací
- příklad:
y = ab + bcd + abd
zákony
- 11 zákonů, slouží k úpravám, zjednodušování a odvozování logických výrazů
Komutativní zákon
a+b = b+aab = ba
Asociativní zákon
(a+b)+c = a+(b+c)(ab)c = a(bc)
Distributivní zákon
a(b+c) = ab+aca+bc = (a+b)(a+c)
Zákon vyloučeného třetího
a+!a = 1a!a = 0
Zákon neutrálnosti nuly a jedničky
a+0 = aa1 = a
Zákon agresivity nuly a jedničky
a+1 = 1a0 = 0
Zákon tautologie
a+a = aaa = a
Zákon absorbce
a+ab = aa(a+b) = a
Zákon absorbce negace
a+!ab = a+ba(!a+b) = ab
Zákon dvojité negace
!!a = a
De Morganovy zákony
!(a+b) = !a!b!(ab) = !a+!b
užití:
k minimalizaci logických výrazů
převody do normálních forem:
- jen součty a negace
- jen součiny a negace
vyjadřování logických funkcí
rovnice
všechny logické funkce jde vyjádřit dvěma způsoby:
- disjunktivní - součet součinů přímých a negovaných proměnných
- konjuktivní - součin součtů přímých a negovaných proměnných
pravdivostní tabulka
tabulka, kde
- sloupce odpovídají členům logické funkce a výsledku
- řádky odpovídají všem možným kombinacím vstupních hodnot
Karnaughova mapa
- matice logických výrazů
- vychází z Vennova diagramu
minimalizace logických funkcí
způsoby:
- odvozováním pomocí zákonů
- pomocí Karnaughovy mapy